
一些原理
Diffusion Model
从一张全是噪点的贴图,随机选择像素点,使其变成选择符合图像条件(符合最大似然估计)的颜色,通过不断的迭代这个过程,最后得到一张符合描述的图像。
但Diffusion Model是一个自回归的模型,需要反复调用自己。Latent Diffusion这个论文就做了个改进,不再对像素进行扩散生成,而是用编码器将图像降维到一个潜空间(Latent),用扩散模型对潜空间内的噪声进行生成,最后用解码器转换到图像。

因为潜空间是一个低维的描述,样本空间比图像的样本空间小,因此运作速度会更快。
Stable Diffusion的结构
Stable Diffusion主要由三个结构构成:
- autoencoder:编码器,负责将图像转换到潜空间;解码器,用于将扩散完成的潜空间转化为图像。
- CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition。
- UNet:扩散模型的主体,用来实现文本引导下的latent生成。

对于SD模型,其autoencoder模型参数大小为84M,CLIP text encoder模型大小为123M,而UNet参数大小为860M,所以SD模型的总参数量约为1B。
图片感知压缩
感知压缩本质上是一个tradeoff,之前的很多扩散模型没有使用这个技巧也可以进行,但原有的非感知压缩的扩散模型有一个很大的问题在于,由于在像素空间上训练模型,如果我们希望生成一张分辨率很高的图片,这就意味着我们训练的空间也是一个很高维的空间。引入感知压缩就是说通过VAE这类自编码模型对原图片进行处理,忽略掉图片中的高频信息,只保留重要、基础的一些特征。这种方法带来的的好处就像引文部分说的一样,能够大幅降低训练和采样阶段的计算复杂度,让文图生成等任务能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛。
Stable Diffusion WebUI里集成的vae,很多人说这个是相当于给生成图套了个滤镜,我觉得恰巧相反,是给训练的模型套了个滤镜。
文生图、图生图和图片修改
根据文本生成图像这是文生图的最核心的功能,下图为SD的文生图的推理流程图:首先根据输入text用text encoder提取text embeddings,同时初始化一个随机噪音noise(latent上的,512×512图像对应的noise维度为64x64x4),然后将text embeddings和noise送入扩散模型UNet中生成去噪后的latent,最后送入autoencoder的decoder模块得到生成的图像。
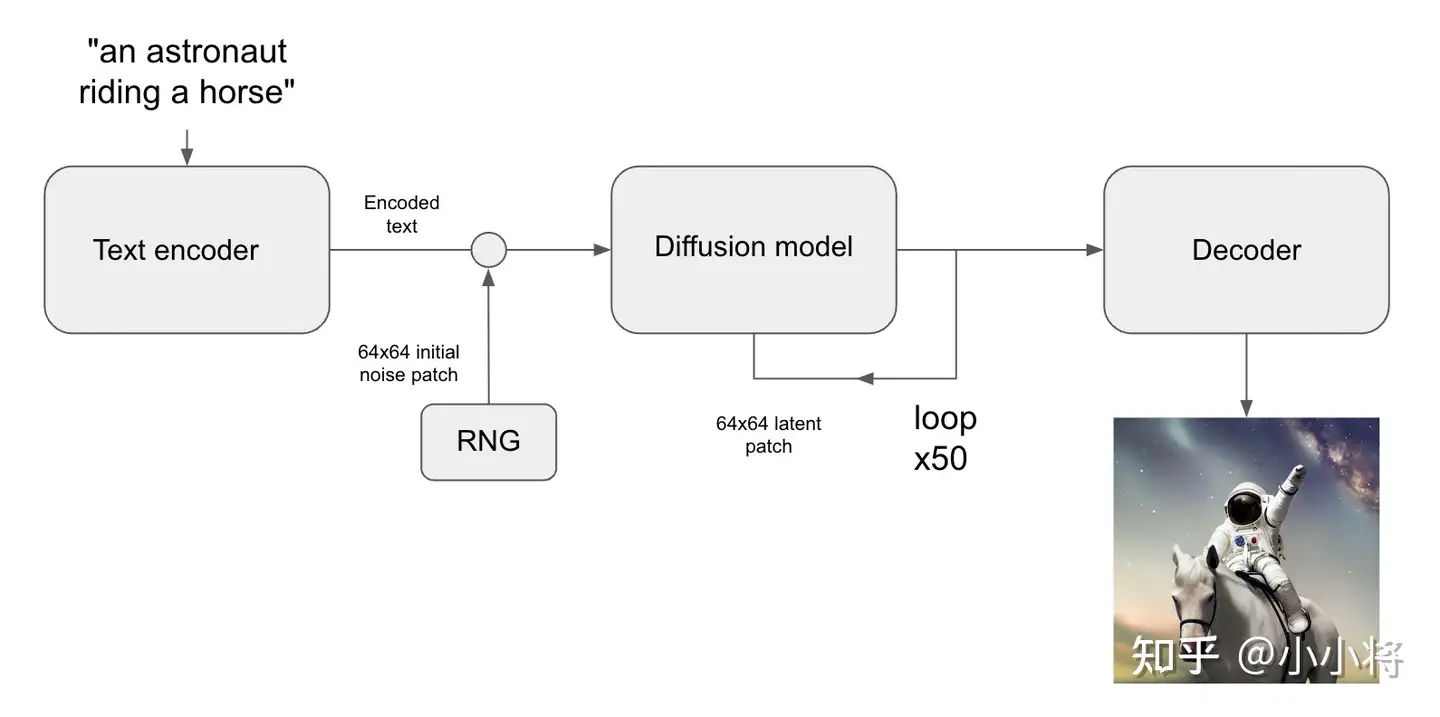
图生图和图片修改的方法也很简单,就是在noise层的时候将现有的图片送进去作为prototype,自然画出来的东西就会跟原先一样。
LoRA
LoRA的全称是:Low-Rank Adaptation of Large Language Models,直译为大模型的低秩适配。原本是NLP中为了解决大语言模型参数过于庞大才出现的,结果在Stable Diffusion中意外火了起来。
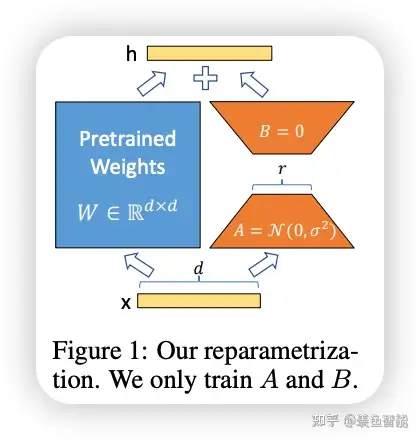
去做任务适配。假设模型在适配任务时参数的改变量是低秩的,由此引出低秩自适应方法LoRA,通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
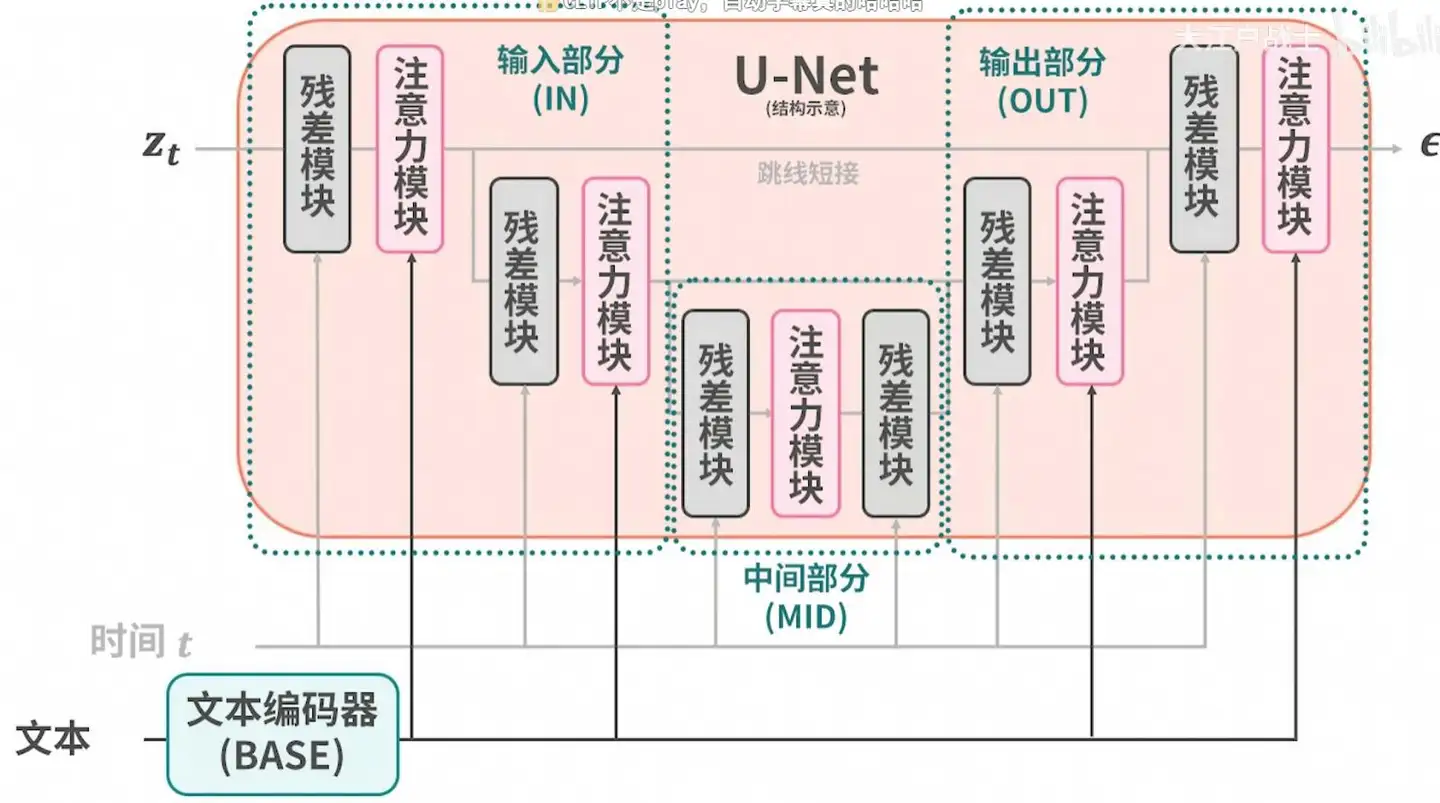
LoRA主要作用在文本编码器CLIP和扩散模型中U-Net部分的注意力模块。理论上不同的基模中U-NET各层作用也应该不太一样,但是由于现在最流行的模型基本上都是基于SD1.5微调的,所以就出现了这种LoRA通用的情况。LoRA作用在17层中,即:
- BASE 1
- IN 2~7
- MID 8
- OUT 9~17
如果使用了LoRA Block Weight插件(在扩展选项卡里安装),则插件作者将7层已经设置好了预设:
| 预设名 | 启用范围 | 权重 |
|---|---|---|
| INS | 17层的2-4层,第一层是base | 1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0 |
| IND | 17层的5-7层,第一层是base | 1,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0 |
| INALL | INS+IND,整个IN部分, 2-7层 | 1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0 |
| MIDD | IND+MID+OUTD部分,5-12层 | 1,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0 |
| OUTD | 17层的9-12层,第一层是base | 1,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0 |
| OUTS | 17层的13-17层,第一层是base | 1,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1 |
| OUTALL | OUTD+OUTS, 整个OUT部分 | 1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1 |
看起来似乎很难懂,有人指出各个层的权重影响的范围如下图所示:
| 影响范围 | 预设 |
|---|---|
| 人物容貌 | MIDD左右 |
| 人物服饰 | IND,OUTD,MIDD |
| 人物姿势 | IND |
| LORA上色风格 | OUTS |
| LORA背景 | MIDD |
| 过拟合 | OUTALL |
必须指出,这个经验只对人物类LoRA生效,如果换了其他的题材的LoRA(比如建筑、风景)则不一定生效。
ControlNet
ControlNet是一种神经网络结构,通过添加额外的条件来控制扩散模型。
将网络结构划分为:1.可训练“trainable” 和2.不可训练“locked” 。其中可训练的部分针对可控的部分进行学习。而锁定的部分,则保留了stable-diffusion模型的原始数据,因此使用少量数据引导,可以保证能充分学习到前置约束的前提下,同时保留原始扩散模型自身的学习能力。
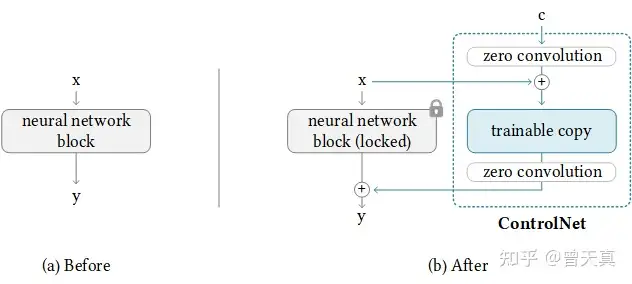
上图的“Zero Convolution”是带有零初始化权重和偏差的1×1卷积。在进行自己的模型训练开始之前,所有零卷积输出都是零,此时模型仍然是原始的Stable Diffusion Model。而在加入自己的训练数据之后,则会对最终数据产生影响,这里的影响,更多是对最终结果的微调,因此不会导致模型出现重大偏离的情况。
我们再往下看整体的模型结构:
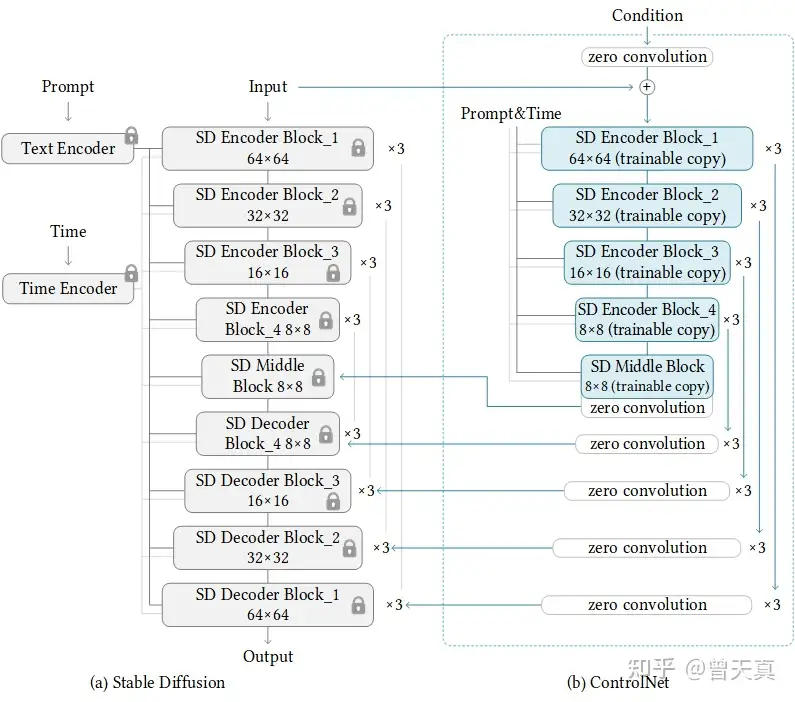
我们从整体的模型结构上可以看出,作者在Stable Diffusion 模型的decode层加入了上述“0卷积层”,以实现对最终模型与训练数据的一致性。
没错你没有看错,网络结构就是这么简单暴力,但有效。
Stable Diffusion及插件的安装
安装
【AI绘画】Stable Diffusion整合包v4发布!全新加速 解压即用 防爆显存 三分钟入门AI绘画 ☆可更新 ☆训练 ☆汉化
使用这个傻瓜一键包即可。
模型下载
模型一般从civitai上挑选心仪的图案,然后进去下载模型:
注意根据模型的类型,下载到不同的地方。更推荐使用civitai插件进行下载。
其他资源可以在启动器界面下载。
ControlNet
模型下载:ControlNet-v1-1
插件和扩展
插件和扩展可以从webui内的扩展选项卡下进行安装,一些未在索引中收录的插件则需要自行下载:
插件安装好后,一般需要点击“重启并应用UI”进行启用,或者直接重启Stable Diffusion也行。
如何绘制一幅图片
基础的步骤
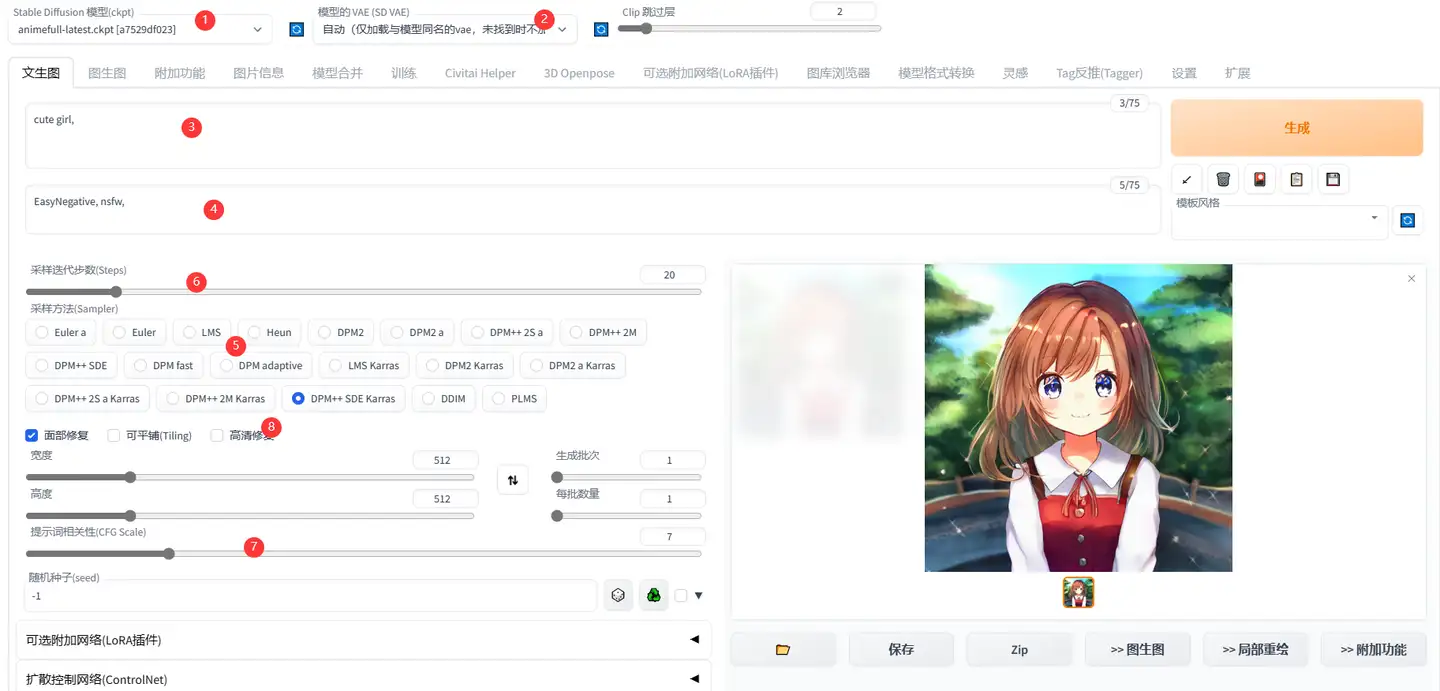
- 选择模型
- 选择VAE自编码模型
- 开始填写正向的Prompt
- 开始填写负向的Prompt
- 选择合适的采样方法(卷积核)
- 选择适合的步数
- 选择CFG
- 一些细小的修补
这些内容在文生图和图生图里都是一样的。
VAE选择
可以不选,据称,三次元风格选择vae-ft-mse-840000-ema-pruned.ckpt,二次元风格选择animevae.pt(说实话我感觉都可以用……)
Prompt的准备
一般,最开始的起手式正向prompt会有以下内容:
highres, masterpieces, best quality, illustration, ultra detail, full body, solo, colorful, hdr基本上起手式就是把握画面的质量、风格、构图和色彩;同样,负向Prompt的起手式也是如此:
bad anatomy, (worst quality:2), (low quality:2), (lowres:2), (grayscale:1.2), ugly, sketch, 3d, realistic, oil painting,比如,上述起手式就描述了我对画面的想法:
- 插画风格
- 细节和完成度要求高
- 色彩鲜艳
- 全身出镜
如果要指定艺术风格,也是可以的,例如CG、写实、抑或是特定艺术家
Prompt的来源
在整合包的小工具合集里有,之后就是根据自己对画面的想象开始设计内容了。
采样方法选择
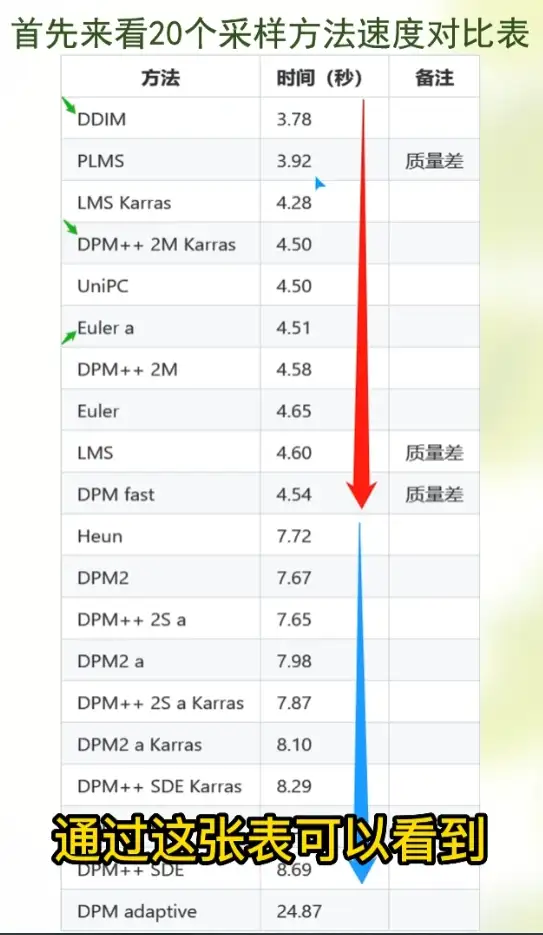
推荐使用DDIM、DPM++ 2M Karras。
采样迭代步数
采样迭代步数意味着从噪点到成图的步数,越高自然画得越精细。

别使用Euler a这类卷积核。用的话,可以把低step但是比较中意的图扔进图生图功能进行redraw。
采样迭代步数的建议是:快速出图看构图和题材,用20~40(视卷积核而定),正式出图80~120。
另外,高采样迭代次数可以不完全有效地对抗手部细节出错和对冲CFG过高出现的构图色彩问题。
CFG
CFG越大,AI发挥空间越小,但越符合提示词描述。CFG低的劣势是构图差、色差对比平淡;CFG高的劣势是可能会过饱和、结构和颜色失调。
建议:描述较少或比较泛泛、需要写意和创意的时候CFG设为2~6;给定严格表示词时使用11~30(需配合特定卷积核);其他时候设为7~10即可。
其他
面部修复用来修复崩坏的面部;高清修复的意思就是先按当前size出图,然后再升采样到更大的图片,适合显存不足、或者想把当前图片高清化的玩家,实质上就是出完图之后自动跑了一次下面说的等比缩放。
图片高清化
某些情况下可能需要小图转大图,例如在这个size出现了好看的原型图,或者是显卡显存不够画不出大图,或者是需要放缩某个区域。
- 将图片发送至图生图,在图生图下用更高的分辨率进行绘制。
- 显存不够的情况下,发送到附加功能下的等比缩放,试用不同的卷积核进行缩放。推荐是用ESRGAN这类方法而不是lancozs等传统插值。
图片细节修缮
有时候,我们对于一些细节会不满意,例如章鱼状肢体、变形的物体等,可以将图片进行局部重绘。
比如此处,我选择重绘眼睛为红色:
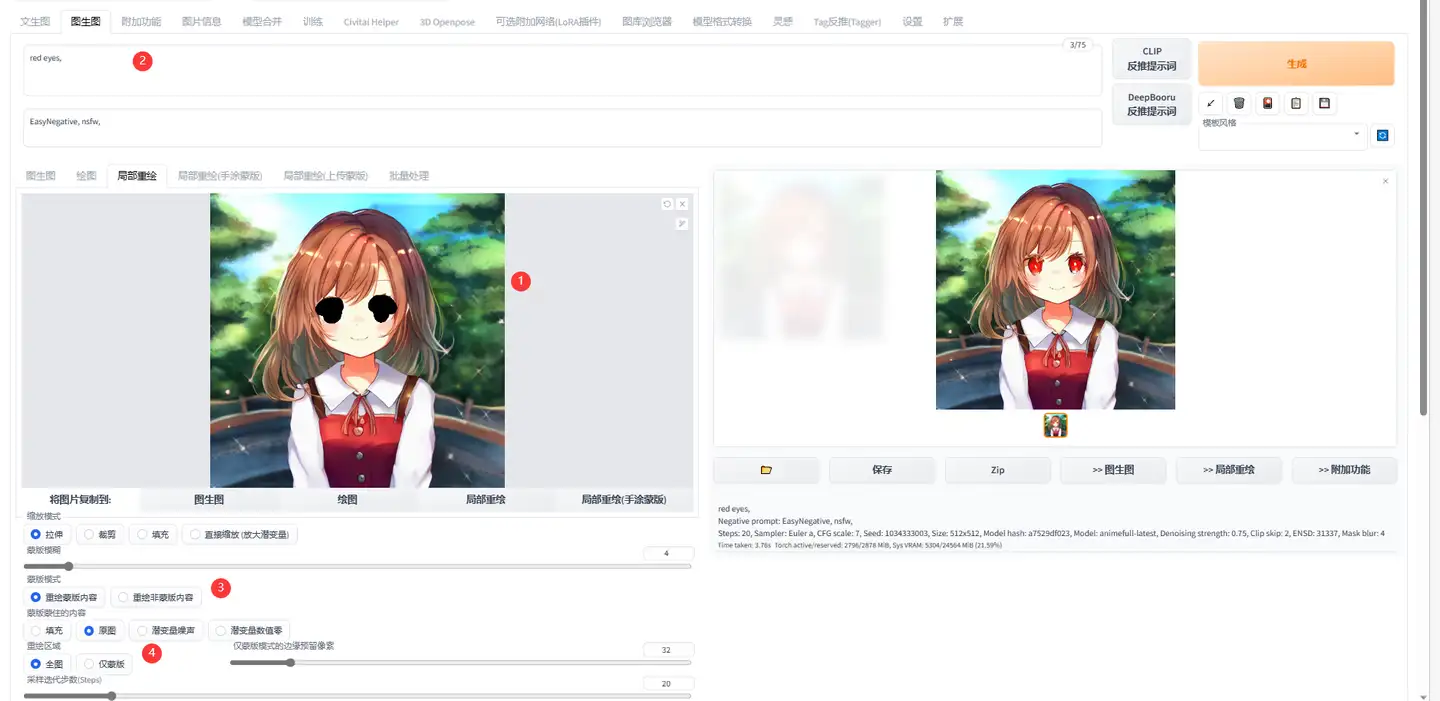
- 绘制图片蒙版,注意调整边缘像素,保证重绘区域的完备性
- 编写要重绘的内容,注意,不是画面中已有的元素,是新的元素!
- 确定重绘范围
- 确定仅重绘蒙版内的内容
另外可以设定蒙版的内容是在原图基础上重绘,还是重新设置潜空间噪声。个人建议是如果蒙版内需要重绘的部分根本不想要,那就重新设置潜空间噪声,反之则根据原图。
Prompt的语法和调度
详细内容可以看:元素同典:确实不完全科学的魔导书 以及后面参考资料里附上的一些东西。
tcbk的个人画图心得:
- 越靠前,权重越高;
- Prompt越短,权重越高;
- 建议使用(xxx: 0.8)的形式来修改权重,更为直白;
- 高权重会导致词语溢出到其他元素上,最好彼此放远一点,如果Prompt本身就很短导致分不开,使用ai is sb进行占位;
- 超过75个token限制的用BREAK进行衔接。
调度顺序
质量控制+画风引导+镜头效果+光照效果+[带描述的主体+主体的次要物体+镜头和光照]*N+全局光照效果+全局镜头效果+画风滤镜
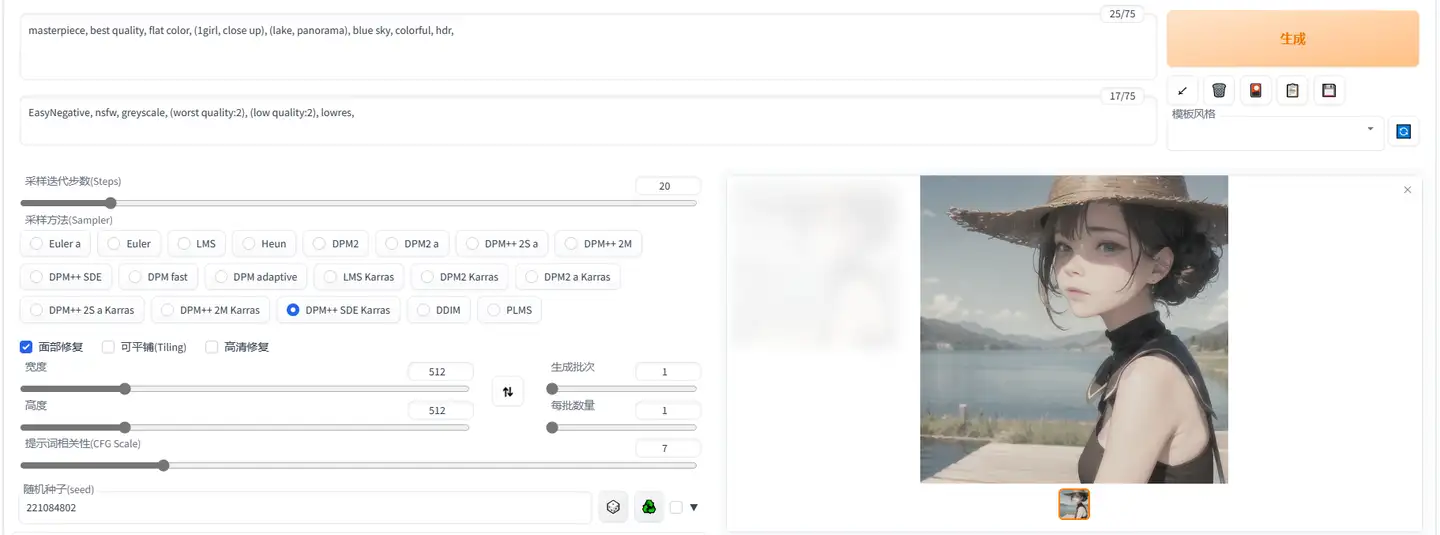
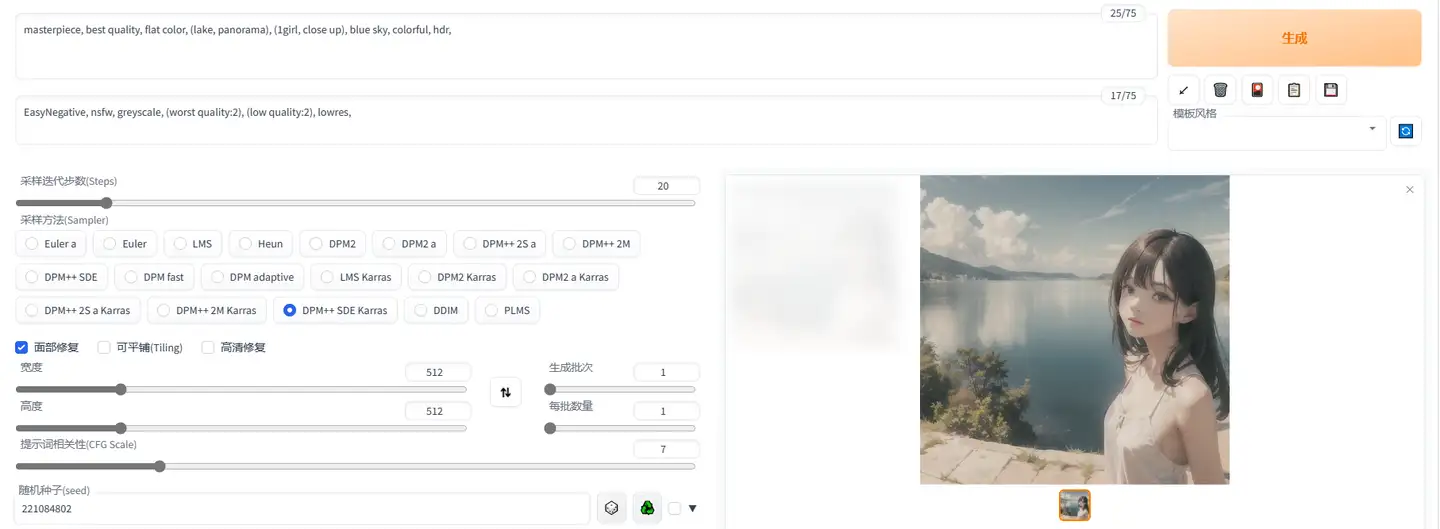
可见,此处仅仅是调换了两个描述的顺序,就导致画面主题中湖的占比提升了很多。
在绘制中,如果发现景别、构图主体出错,可以先以最短的prompt进行绘制,满意之后再开始丰富画面。
使用LoRA控制绘制图片
下面以BreakDro固定设置、固定seed下的图片举例,以下为原图:

使用插件类LoRA
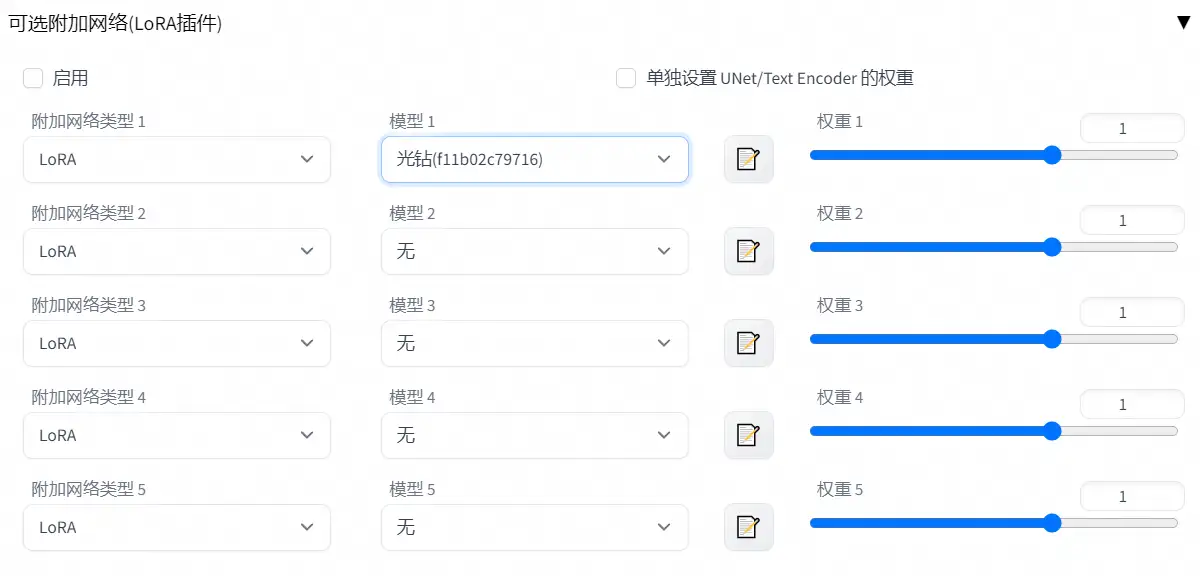
插件类LoRA在图片生成参数的下方,操作非常的简单,就是是否启用、调节权重。使用光钻LoRA权重为1.0和0.4的效果:


可见,这是个公主风格的LoRA。
使用模型类LoRA
在Prompt里插入:
<lora:LoRA名字:LoRA权重>
<lora:MoXin-1.0:0.4>即可调用LoRA。使用墨心1.0 LoRA权重为1.0和0.4的效果:


很明显,完全使用墨心的状态会直接炸炉,因此不太推荐。
分层控制LoRA
安装了前文提到的LoRA Block Weight插件后,可以用下面的方法指定预设或者各层权重,插件的界面也是在图片生产参数下方:
<lora:MoXin-1.0:0.4:INALL>
<lora:MoXin-1.0:0.4:1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0>以下是墨心1.0 LoRA权重为0.4,分层控制使用预设INALL的效果:

关于各层的权重和对应的效果,需要针对各个LoRA和模型自行把控。
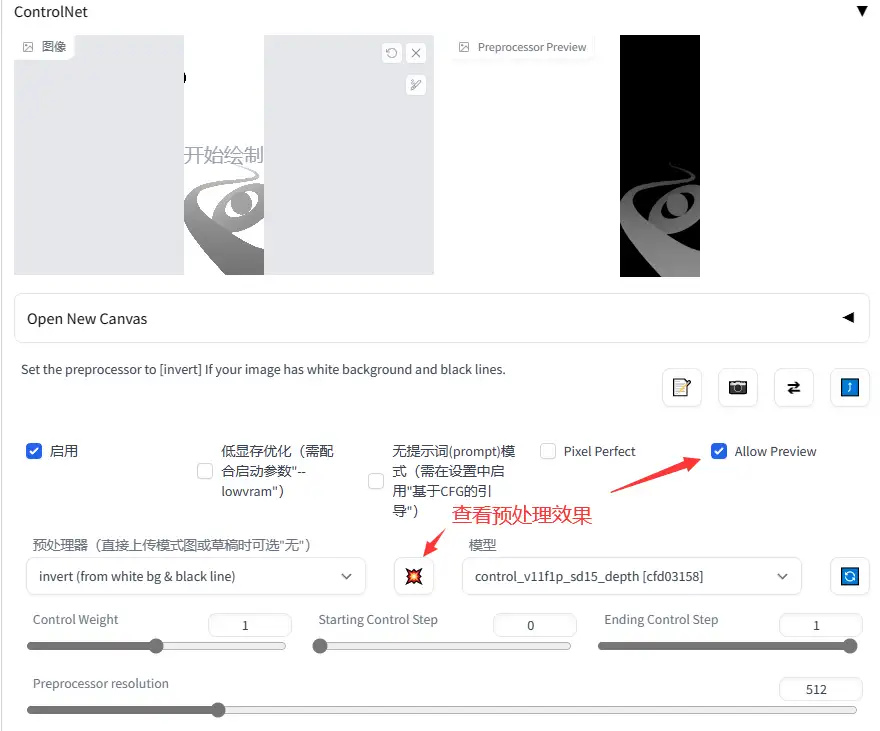
使用ControlNet控制绘制图片
移步参考资料【9】:https://zhuanlan.zhihu.com/p/607892849
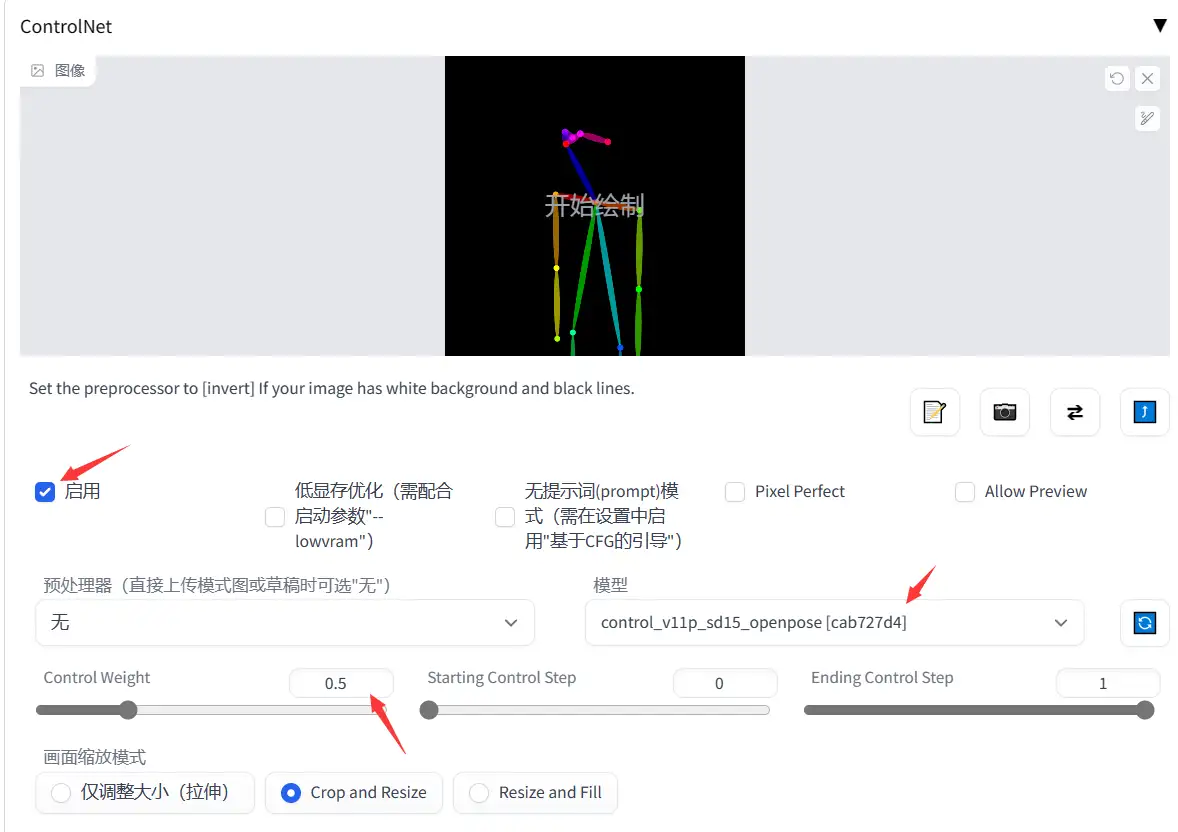
基本上就是:
- 点击启用
- 选择预处理器,如果不是已经做好的openpose图或者深度图,最好做一次预处理
- 选择模型,这个自家图用什么,看名字就知道
- 调节权重
这里补充下个人的使用感受:
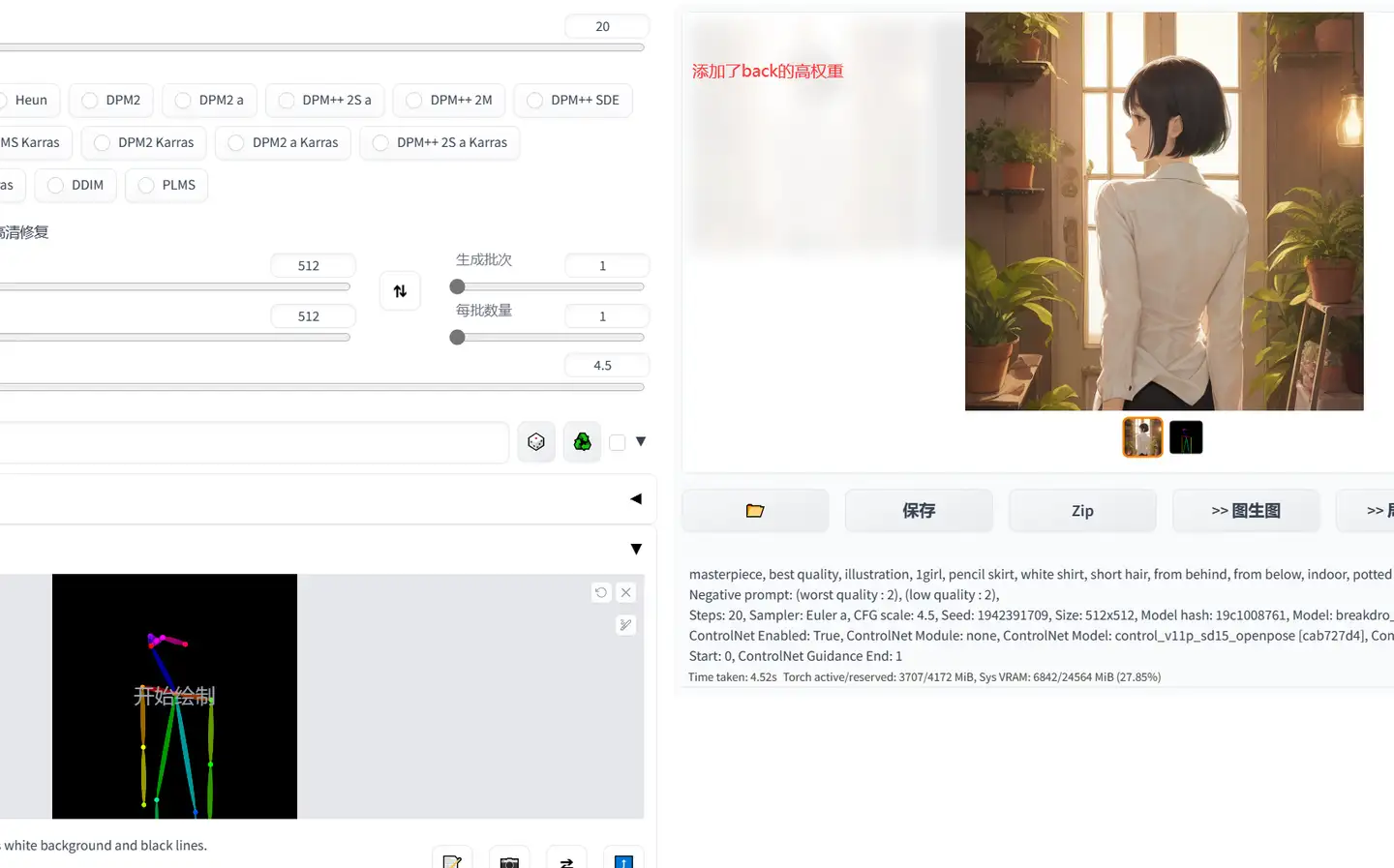
个人感觉,如果使用露头露脸的OpenPose,则权重不宜太大,容易导致脸部错误;
另外,Prompt如果有描述的部位和OpenPose冲突,容易打架导致出图冲突,如下图所示,我添加了back、from behind,导致整个图并没有按照OpenPose的构型走。
使用OpenPose编辑器控制图片
推荐使用sd-webui-3d-open-pose-editor这个插件,在扩展里即可下载。
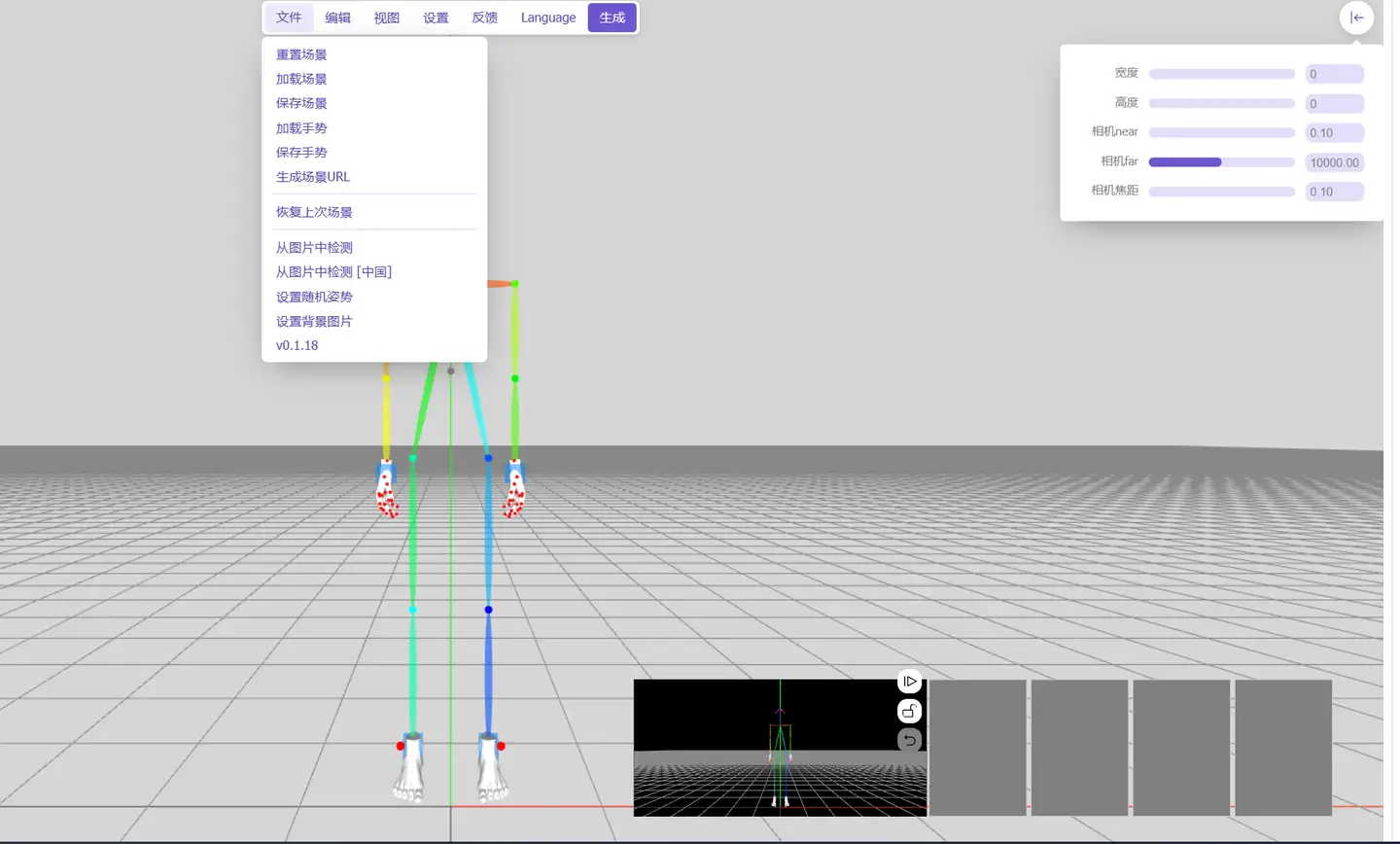
优势在于可以以极高的控制度去控制人物,缺点大概就是可控制项太多了,咱看了就头晕。
使用Segment Anything控制图片
如果使用局部重绘功能自己手动画,既不方便,效果也不好,不如直接上之前大火的Segment Everything。
SA插件地址:https://github.com/continue-revolution/sd-webui-segment-anything
SA模型地址:https://github.com/facebookresearch/segment-anything/
使用方法,移步参考资料【10】:https://zhuanlan.zhihu.com/p/623040112
(补充,我这里用不了这个插件,报错)
针对特定题材训练一个LoRA
后续补充
Stable Diffusion和游戏开发
PBR贴图生产
使用Stable Diffusion作为启动点,辅以其他软件,可以做到直接产出PBR贴图。
以Stable Diffusion 1.5模型,勾选平铺(Tiling),用下述语句可以得到一个实木纹理:
top down photo of wooden floor, 8k, detailed, intricate,

之后使用MindTex 2绘制法线——下面那个Materialize也可以,但我觉得这玩意儿更加舒服。
Steam有售:https://store.steampowered.com/app/441770/MindTex_2/
或其他你知道的在线网站,或者Substance Designer也行(但这玩意儿太笨重了)
生成Roughness/Metallic/AO用的是Materialize,神海的不少资源都用这个产出的(居然是用Unity写的,乐)。
截取游戏中的深度图进行创作
ControlNet既然支持深度图控制,我特么直接从游戏里截出深度图!深度缓冲可以从截帧软件(GPA、Renderdoc)中拿去,也可以从游戏引擎里获取(Unity的话直接从Frame Debugger里抠)
~~(此处涉及项目图片,已删除)~~
以下是固定种子下,未启动和启动深度图作为ControlNet输入的效果:


使用Houdini进行创作
首先,使用Houdini出深度图,方法是在通道中开启Depth输出:
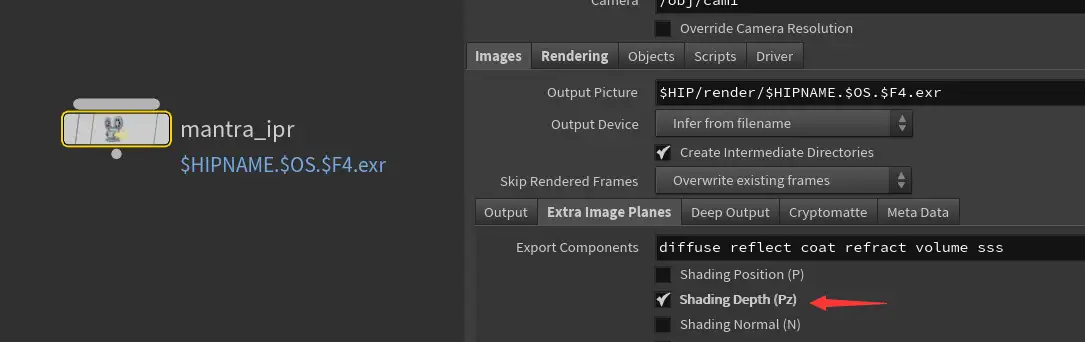
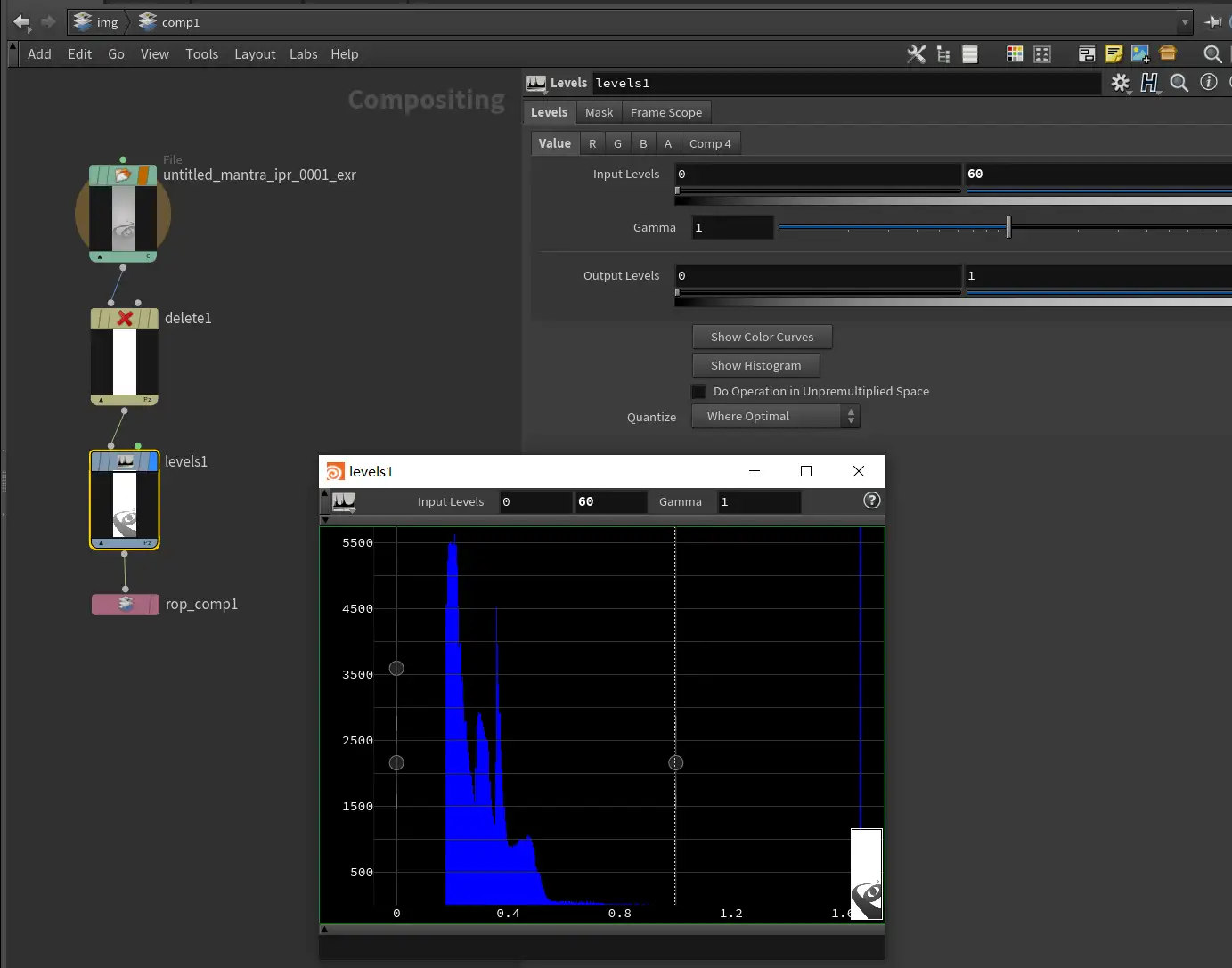
合成时候小小调整一下曲线,使值落在0~1之间。使用的时候反转一下。
后面会有一个我用Houdini + Stable Diffusion一起组合做海报的案例。
和谐化元素
在制作UI、立绘、宣传图等内容的时候,可以快速使用SD对画面中不符合要求的元素进行合规处理。
啊,当然我不是美术,我就这么一提。
概念产出
~~(此处涉及项目图片,已删除)~~
这是裸装血骑士,从RenderDoc里拿到深度图,直接写:
(photorealistic:1.5), best quality, 8K UHD RAW Photo, ultra detailed, physically based rendering, male vampire lord, holding spear and necklace, strong, Roman gladiator, heavy armor, Circular platform, strong shadow, top light,
直出罗马重甲风格:

此外,更换不同的模型和LoRA还可以绘制不同题材、景别的场景,例如服装、家具、科幻、野外等,这里就不再赘述了。简单举个例子: https://www.zhihu.com/question/595905437/answer/2989735982
常见的Trick
横幅画面出现重复
虽然SD的架构上支持任意尺寸的图像生成,但训练是在固定尺寸上(512×512),生成其它尺寸图像还是会存在一定的问题。解决的方法有:
- 使用经过多尺度策略训练的模型
- 使用”solo” prompt
- 尽可能描述画面的背景使Stable Diffusion有物可画
拉高CFG后出现色彩爆点

建议选择对CFG饱和度不敏感的采样方式。
感觉画面色彩不明显
在正面Prompt里添加hdr,在负面Prompt里添加(grayscale:1.0),并调节权重直到你满意。
原文链接:https://zhuanlan.zhihu.com/p/623987628